Structured Decoding with Vision Language Models
Vision Language Models (VLMs) combine vision and language understanding in a unified way.
In the image below you can see how an image of a pile of wooden logs is cut up in patches and then typically processed (à la LLaVa). The patches are encoded with a vision model. The text is tokenized and projected onto the same embedding space. Then, vision and text embeddings text embeddings are concatenated and finally fed through a decoder transformer to output an answer.

In code, mixing an image with a prompt typically looks like this: (source):
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
inputs = processor(prompt, image, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=100)The problem is that sometimes you want your VLM to output tokens in a specific format.
Let's say you want to annotate a dataset for image styles and you want the responses to be in the following format:
{
"short_caption": "Close-up of a Chalice cup on a cloth background",
"style": "Photorealism",
"source_type": "Digital Art",
"color_palette": ["blue", "red", "green"],
"tags": ["Chalice", "cup", "metallic", "cloth", "still_life"]
}You can ask the LLM nicely to adhere to this schem, but you may find this often to be a hit-or-miss strategy.1
However, if you want to be more certain - and in some cases even speed up inference - you should look at Structured Decoding.
Constrained Decoding
What if you can limit the output token sampling to the characters that you know follow a specific pattern? This is exactly what constrainted decoding does.
The image below shows a small example where we have decoded a part of the schema and are now at the token that represents the amount of items. The constraints are visualized by a mask that is applied to the logits of the digit tokens "0"-"9".
Sampling is then done on only this range. In this case, the "3" token is sampled.
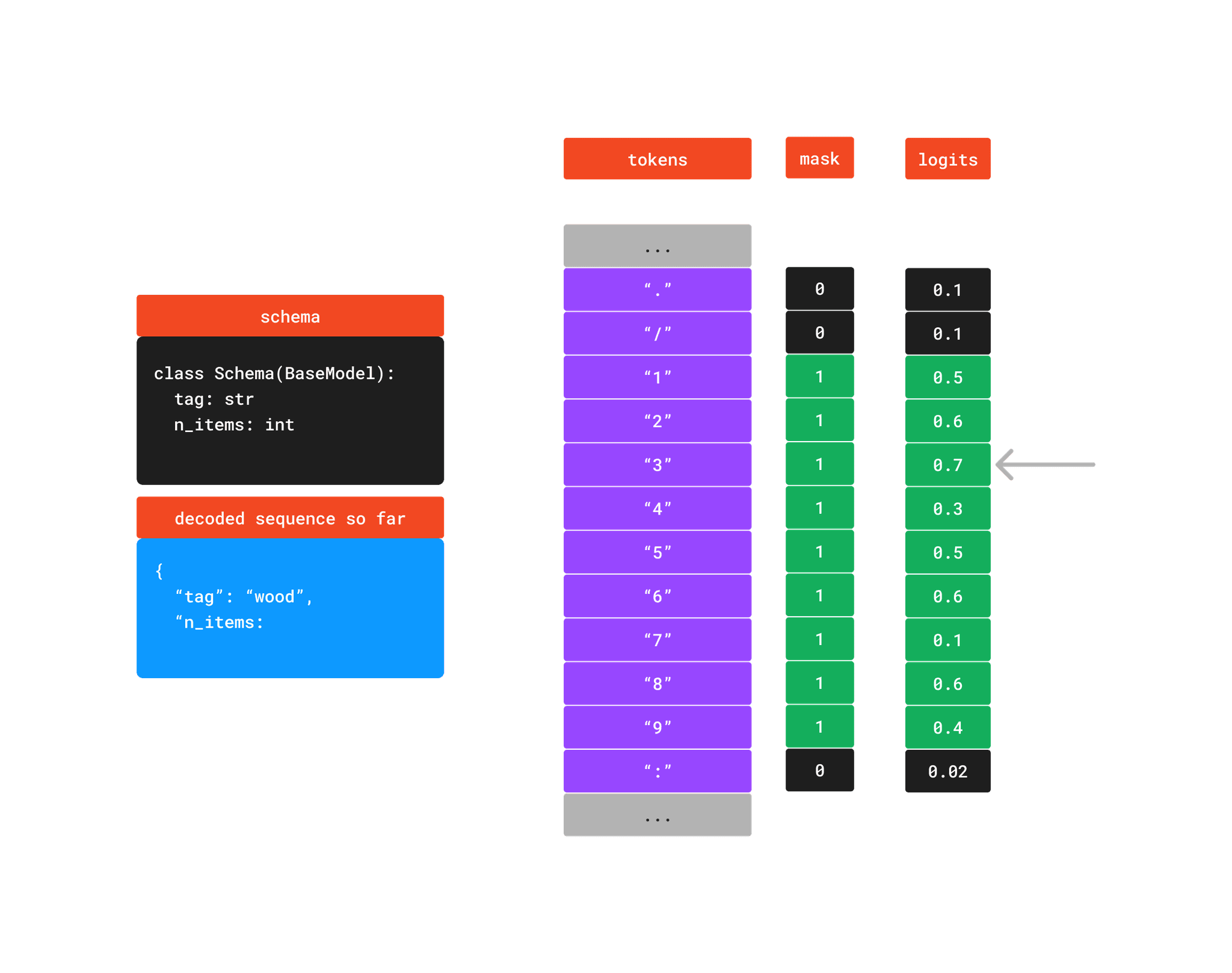
For the following example we'll be using the Python package outlines. Outlines constructs a finite state machine (fsm) for the grammar of a supplied schema. During sampling, each sample step of the output sentence then updates the state of the fsm and makes sure that certain tokens are masked/available at the right time.
Code Example
import os
import json
from pathlib import Path
from typing import Literal, List
import outlines
import torch
from PIL import Image
from pydantic import BaseModel, Field
from rich import print
from transformers import Qwen2VLForConditionalGeneration
def img_from_path(path, largest_size=512):
img = Image.open(path)
width, height = img.size
scale = largest_size / max(width, height)
return img.resize((int(width * scale), int(height * scale))).convert("RGB")We can define an output schema by means of a Pydantic BaseModel class:
class Style(BaseModel):
short_caption: str = Field(max_length=100)
style: Literal[
"Realism", "Impressionism", "Abstract", "Other"
]
source_type: Literal[
"Photography", "Digital Art", "Graphic Design", "Other"
]
color_palette: List[str] = Field(max_length=3)
tags: List[str] = Field(max_length=5)Then we instantiate an outlines vision model and give it our schema:
model = outlines.models.transformers_vision(
"Qwen/Qwen2-VL-7B-Instruct",
model_class=Qwen2VLForConditionalGeneration,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
image_data_generator = outlines.generate.json(model, Style)Let's load in some images to test.
query_image_barracuda = img_from_path("encoders_dev/test_images/barracuda.png")
query_image_chalice = img_from_path("encoders_dev/test_images/chalice.png")
# without few shot
out = image_data_generator(
prompts="|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe the style of this image in json format:<|im_end|>\n<|im_start|>assistant\n",
media=[query_image_chalice]
)
print(out)
# Style(
# short_caption='Close-up of a Chalice cup on a cloth background',
# style='Photorealism',
# source_type='Digital Art',
# color_palette=['#E8006B', '#15042B', '#21213D'],
# tags=['Chalice', 'cup', 'metallic', 'cloth', 'still_life']
# )Nice! However we might be able to do a bit better. Notice that the colors of the color_palette are given in hexadecimals. Can we make it more human readable?
Let's try a few-shot approach where we first give the model an example of how we want the schema to be filled in.
few_shot = (
Style(
short_caption="blue and yellow barracuda, plants",
style="Contemporary",
source_type="Digital Art",
color_palette=["blue", "green", "black"],
tags=["line drawing", "water", "fish"]
),
query_image_barracuda,
)
out = image_data_generator(
prompts=f"|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe the style of this image in json format:<|im_end|>\n<|im_start|>assistant\n{few_shot[0].model_dump_json()}<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe the style of this image in json format:<|im_end|>\n<|im_start|>assistant\n",
media=[few_shot[1], query_image_chalice]
)
print(out)
# Style(
# short_caption='silver chalice',
# style='Contemporary',
# source_type='Photography',
# color_palette=['silver', 'pink', 'blue'],
# tags=['metal', 'artificial light', 'abbey', 'ritual']
# )Even better! The colors are now more readable.
Footnotes
-
Some services/models offer json-mode inference; https://platform.openai.com/docs/guides/structured-outputs#json-mode ↩