Generative AI in Gaming
With the recent massive explosion in generative image models like DALL-E 2 and Stable Diffusion [SD], I was eager to explore use cases of these models within the context of Future of Gaming DAO.
What are DALL-E 2 and Stable Diffusion?
DALL-E 2 and Stable Diffusion are machine learning models that can be used for txt2image translation. This means that you can input a prompt e.g. "cyberpunk homer simpson playing poker" and the model will output an image that corresponds to this prompt. The models are trained on huge datasets of web-scraped caption-image pairs.
Next to text2image, these models can also start with an existing image and translate it into an image that matches the user's text or prompt. This is referred to as img2img.
What is the Future of Gaming DAO?
"The core FOGDAO team consists of dedicated investors, operators, and content creators with a passion for Web3 games. We aim to create a place where anyone can express their ideas, participate in constructive debates, and contribute to an ongoing discussion around where the gaming industry is heading." - FOGDAO Discord
In the first part of this post, I'll suggest a couple of ways in which generative AI could be used in gaming from both a gamer's and a developer's point of view. In the second part, I'll show you some things I've been experimenting with in collaboration with Nico and sniper.
Note: there are other domains where generative AI is causing groundbreaking innovations, such as text and audio, but in this post, we focus on the visual aspect.
Part 1: The latent space is the limit
Diffused skins
View tweet by @imkairu ↗Cosmetics in gaming are a big deal. The play with generative AI here is that gamers can either customize their own skins or make them from scratch. They'd just have to find the right words to massage the generative model into finding the desired look.
The technical caveat is that the underlying mesh needs to accommodate the generated texture, as models like SD only output in 2D pixel space, not in 3D space. Even more importantly, generative skins become tricky when you consider a substantial driving force behind the current cosmetics revenue: scarcity. Both players and publishers enjoy and exploit this constraint, respectively, and generative AI is kind of at odds with scarcity. I believe generative skins will first be used by smaller and more niche developer studios that dare to break and innovate on existing revenue streams
Highly specialized customization engines are also a viable target. In Forza Motorsports, players can combine layers of primitive shapes or "vinyls" to create their custom liveries. And yes, some players take pride in making fully-fledged anime liveries from scratch.

For liveries, the existing primitives-based approach makes sense, but not all people have time to mix and match 2000+ layers. I think it's fairly feasible to hook up SD from multiple viewpoints and enforce some symmetry constraints to create a livery that matches your car's curves. (The sponsor names probably won't make sense as SD struggles with generating words.)
Remastered editions and the modding scene
AI has already been used to help upscale textures to higher resolutions. However, with the new wave of generative models, we'll likely be able to experience a whole new fidelity.
View tweet by @mcreed ↗
Not only will the fidelity of upscaled textures improve, but the road to automating the translation of texture packs into completely different modes and styles also lies wide open. For example, a howtogeek article shows you how to create your own Minecraft texture pack using Stable Diffusion. Soon, we will likely see a boom in autogenerated texture packs.
Remastering on-the-fly
Looking beyond static texture packs, @ScottieFox has been experimenting with a real-time generative VR experience.
View tweet by @ScottieFoxTTV ↗The specific tech stack behind it hasn't been uncovered, but it seems they carefully blend and project img2img generations onto an environment sphere.
Anyhow, this demo paves the way to on-the-fly customizable, totally immersible experiences. I project this will become one a popular way to experience a new kind of generative media that is coming our way.
Bring Your Own Latent Vector
One current pain point with using stable diffusion is that it's very tricky to generate coherent frames over a long time horizon in e.g. animations. However, for pinning the content among images that don't need to come from the same scene, two community-vetted methods exist; textual inversion and dreambooth.
Textual Inversion3 is a method to fit a specific concept onto a new prompt token e.g. S*:

This special token can then be used to manipulate subsequent generations. Textual inversion opens up the possibility to curate a custom set of tokens and underlying latent vectors which you can use to share or mix with other people/engines. Given that a gaming ecosystem uses a similar generation engine, it might even be possible to carry over your custom latent vectors among games.
The second method is introduced by the dreambooth paper4:

It follows the same principle as textual inversion, but it also yields a new and more specialized version of stable diffusion. This method can be useful for developers that want character, object, or world consistency within their (player-focused) generations. More on that later.
Interpreting on-chain game data
Realms is a "Massively multiplayer on-chain game of Economics and Chivalry, built on Starknet and Ethereum". In a nutshell, you manage and govern kingdoms, build armies and go to war with the kingdoms of other players. It's akin to the web2 games Tribal Wars and Clash of Clans but innovates by leveraging the affordances of web3 such as proof of ownership, composability, and decentralization.
Recently, they've been working on ways to incorporate generative AI into their on-chain game. One interesting use case is that of interpreting blockchain battle events between two kingdoms. As a small test, which format is more engaging to you?
This:
{
"eventId": "384467_0000_0006",
"realmId": 14,
"realmOwner": "loaf.eth",
"realmOrder": "Perfection",
"eventType": "realm_combat_attack",
"data": {
"success": true
}
}Or this:

Even though you may have lots of imagination, you probably picked the latter.
I believe that generative AI shines here. First and foremost, writing data on the blockchain is expensive, so we want to keep it at a bare minimum. Engines such as SD enable us to beautifully interpret data primitives such that the events become more engaging for the end users. It becomes a lens by which we can interpret data. Second, there will be a lot of raiding and attacking in the game and generative AI can generate almost infinite variations in rapid succession.
In its current version, the generated images are posted by a Discord bot and shown on the game's client:

In the future, techniques such as textual inversion could be used to pin player-preferred styles or objects in images. For example, a user can find the textual inversion for a specific castle they like and save that in their account. The generation engine can then use the user-specific castle token to always show that castle when a user's realm gets attacked.
Generative assets
There's more good news for developers of games; it will become easier and easier to generate high-quality game assets. Check out this post from @emmanuel_2m, who used a couple of tricks with SD to generate some fantasy potions.
View tweet by @emmanuel_2m ↗@emmanuel_2m and other users are also applying this to whole sprite sheets! This is yet another use case that makes me believe that generative AI will become a critical tool for game devs.
Differentiable rendering
Images are great, but what about 3D objects? To understand what is possible in the 3D domain, we can start with a rendering pipeline of a typical 3D game:
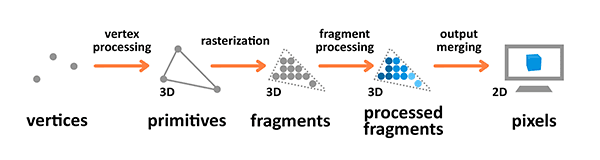
Here, the process starts with a collection of vertices (mesh), which is transformed and colored, and finally presented on screen.
In machine learning, one trick is to make each orange arrow differentiable. This means that we can relate each output to its inputs through continuous functions. In the end, this allows us to check if a render corresponds to what we want, and optimize its underlying mesh and textures. Engines that allow this kind of optimization are called differentiable render engines. (Note that not all differentiable render engines need to optimize a mesh. E.g. NeRF optimizes volumetric densities.)
One recent mind-blowing method that utilizes both a diffusion model and a differentiable render engine (NeRF) is called DreamFusion6. A user can input any text, e.g. "a knight chopping wood" and DreamFusion will give back a fully textured mesh that corresponds to the prompt. Here are some examples that were generated using this technique:
Some drawbacks are that it takes quite a while to optimize; 5 hours on a beefy GPU per object. Furthermore, the meshes are not fully game-ready as they are just inferred from a distance function and are not directly optimized for ease of animation and rigging. Both of these shortcomings seem just a matter of time to be solved by academia/industry though.
I personally think that differentiable rendering is one of the most promising techniques for the future. I still can't wrap my head around a future where differentiable rendering is made hyper-efficient (i.e. realtime) and we have orders of magnitude more compute available.
Part 2: FOGDAO behind the scenes
Character creation screen
Given the expressive nature of diffusion models and that we wanted to create something interactive with a gaming component, our initial idea was to create a sort of character creation screen.
View tweet by @TheActMan_YT ↗The underlying question was the following: what if instead of finetuning a bunch of sliders, you could simply enter a prompt to get fairly close to your end result?
Composable init templates
We tried messing around with composing init images based on the trait choices. For example, consider the following traits and choices:
# format: trait = {choice : mask_path}
attribute = {
"visor": "visor.png",
"crown": "crown.png"
"amulet": "amulet.png",
}
background = {
"scifi": "scifi.png",
"fantasy": "fantasy.png",
}A function would then select a choice from each trait, and place the corresponding mask on top of the init image:

The init images are purposefully kept gray because we didn't want to bias the final output. We also added gaussian noise of different levels onto each layer.
Next, we would do an img2img pass and get:

These look pretty bad! 😅 Next time, we better avoid injecting the init templates with our own noise.
Robots
Back to the drawing board. We got rid of the init templates and decided to finetune our prompt. We got a bit sidetracked by a robot corner of the latent space:
Experimenting with overal vibe/faction:


Going for more of a "pfp" look:

This is starting to look like something, but if we would consider turning this into a collection of 1000 images, it might turn out a bit bland. Let's keep the pfp look, but spice it up a bit.
Prompt sampling
First, we parametrically built up our prompt for testing purposes:
from random import choice
races = ["ghost", "dragon", "monkey", "seer", "elf"]
styles = [
"as a metal gear solid character",
"as a pokemon catcher",
"as a world of warcraft character",
]
def sample() -> str :
race = choice(races)
style = choice(styles)
return f"a portrait painting of a {race}" +
f" in the style of {style}, highly detailed, vignette"Now everytime we call sample(), we will get a different prompt. (In the end a user should be able to choose the values.)
Generation pipeline & custom frontend
We wanted to visualize the quality of the images over a larger amount, so we created a custom backend and frontend. The flow is as follows:
- Use
sample()to sample choices from the trait lists and build a prompt. - Send both the prompt and some metadata (which choices were selected) to the backend.
- The backend receives the request, starts a job, and saves all information.
- After the images are generated, we can call the backend through a react client to get a better grasp of what works and what doesn't work.

We can select which values change on each axis. In the image above, the columns show different races, while the rows show different styles.
Each combination of race and style is grouped into an ImageIsland. If you click here you can see more generations and you can even upvote or downvote some generations to select which ones are visible in preview.
Results
These are random cherrypicked images from different styles and races:








I think these are starting to look pretty cool, but unfortunately we shelved this project for the time being.
Closing words
The journey of generative models has been amazing so far and I'm super keen on developing new workflows to use these powerful tools.
If you have any remarks or questions, feel free to DM me at @rvorias.
Sources: